The Cost of Context: Optimizing Enterprise AI Architectures for Scale
At a Glance: From Demo to Production
- The Problem: Most enterprise AI projects fail in production due to Context Overload, Inference Costs, and System Latency.
- The Solution: Shark AI's architectural framework using Intelligent Triage, Semantic Caching, and Parallelized Retrieval.
- The Shift: Moving from "Prompt Engineering" to "Architectural Engineering."
- The Result: Predictable costs, sub-2-second responses, and true enterprise scale.
The Opening Scene: The Demo That Worked (Until It Didn't)
Picture this.
Your enterprise has spent years accumulating 50,000 internal policy documents, millions of customer support transcripts, and a decade of project reports. You want to build a "Truth Engine"—an AI that allows any employee to ask: "What was the technical resolution for the Client X project from 2023?"
You build a basic RAG (Retrieval-Augmented Generation) system.
It works beautifully for the first 100 documents.
Then you load your entire knowledge base.
And the system hits a wall.
The Three Walls That Kill Enterprise AI
Wall #1: The Context Overload Problem
You send massive chunks of documents to the model. The AI gets "lost in the middle." It hallucinates details because it cannot distinguish between critical facts and boilerplate text.
The result: Confident-sounding wrong answers.
Wall #2: The Latency Tax
Every query takes 45 seconds because the system processes a bloated context window.
The result: Your team stops using it after three attempts.
Wall #3: The Budget Explosion
You are paying for millions of input tokens every time someone asks a simple question.
The result: Your cloud bill goes vertical. Finance kills the project.
This is the "Cost of Context" at scale.
At Shark AI Solutions, we don't just "plug in" a model. We architect RAG engines that treat your data as a high-performance asset—not a burden.
The "One-Size-Fits-All" Trap
Many developers treat AI like a blunt instrument: they feed every single piece of data into the "brain" of the model.
For an enterprise handling high-volume data, this is a massive inefficiency. It's like trying to drink from a firehose. You end up paying for a flood of data you don't actually need, and the system becomes sluggish.
The Example: If you are analyzing 100,000 product reviews, 40% might be "no-opinion" stars or simple "Great product!" comments. Sending these to a frontier LLM costs thousands of tokens for zero actionable insight.
We strip these out at the start.
Our Pillars of AI Efficiency
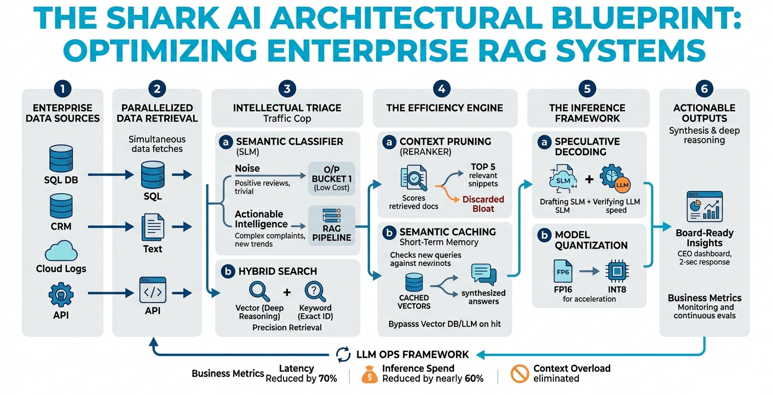
1. The "Traffic Cop" (Intelligent Triage)
Instead of asking our "Master AI" to read every trivial customer comment, we build an intelligent triage layer. It acts like an expert clerk: it instantly identifies what is "noise" and what is "intelligence."
Example: In our brand engine, we implemented a keyword-based and small-model classifier that routes "positive sentiment" reviews to a pre-defined bucket and only sends "complex complaints" or "new trend mentions" to the advanced reasoning engine.
The Result: Reduced total inference spend by nearly 60%.
2. The "Short-Term Memory" (Semantic Caching)
We don't make the AI re-read the entire history of the brand from scratch every time. We use Semantic Caching—a digital "short-term memory" that keeps the most relevant insights ready for immediate recall.
Example: When an executive asks, "How did our brand sentiment change after the Q1 launch?" the system retrieves the previously calculated sentiment vectors for that specific timeframe rather than re-processing the entire Q1 dataset.
The Result: Response time cut from 30 seconds to under 2 seconds.
3. Massively Parallel Data Retrieval
Enterprise data is rarely stored in one place. Our architecture uses parallel processing to pull information from SQL databases, CRMs, and cloud logs simultaneously.
Example: When a user queries a brand insight, our engine simultaneously queries the "Review Database," the "Social Media API," and the "Support Ticket Logs" in parallel threads.
The Result: Eliminated the bottleneck of waiting for sequential database responses.
Advanced Techniques to Boost Inference Speed
To keep an enterprise chat engine lightning-fast, we employ these specialized techniques:
| Technique | What It Does | Impact |
|---|---|---|
| Hybrid Search | Combines vector embeddings with traditional keyword (BM25) search | 100% accurate retrieval for specific Part IDs |
| Context Pruning (Reranking) | Retrieves 50 documents, scores them, sends only top 5 to LLM | 90% reduction in context token spend |
| Model Quantization | Reduces model weight precision for speed | 40% faster inference |
| Speculative Decoding | Small model "drafts" tokens; main model verifies | 2-3x faster generation |
Why In-House AI Teams Often Struggle
Many enterprises attempt to build these systems internally with generalist software teams. They fail because they treat AI development like standard application development.
They ignore:
- LLM Evals (No way to measure if the AI is improving)
- Vector Database drift (Embeddings become stale over time)
- Inference cost volatility (No predictability in cloud bills)
At Shark AI, we have already solved these "Day 2" operational problems. We don't just build the engine; we provide the LLMOps framework that keeps it running reliably over time.
Related Reading: The Prompt Engineering Trap | The Fine-Tuning Fallacy
The Decision Maker's Bottom Line
When we build a chat engine, our goal isn't just to make it "talk." It is to make it the most efficient intelligence layer in your company.
| Metric | Traditional RAG | Shark AI Architecture |
|---|---|---|
| Response Time | 30-60 seconds | <2 seconds |
| Token Cost per Query | $0.05 - $0.50 | $0.005 - $0.02 |
| Context Window Usage | Bloated (80% waste) | Pruned (95% relevant) |
| Scale Ceiling | 10k-50k docs | 1M+ docs |
| Cost Predictability | Volatile | Predictable |
The Closing Scene: Stop Playing. Start Engineering.
Here's what most AI vendors won't tell you:
You don't need a bigger model. You need a smarter architecture.
You don't need to throw more data at the problem. You need to triage, cache, and parallelize.
You don't need to accept 45-second latency. You need sub-2-second responses.
The technology exists. The patterns are proven. The cost is predictable.
You just need the right architectural partner.
Your Move
You have two choices:
Option A: Keep treating AI like a magic black box. Keep paying for bloated context windows. Keep waiting 45 seconds for answers. Keep watching your cloud bill explode.
Option B: Call us. Let us audit your current RAG pipeline. Let us show you where you're burning tokens. Let us build you an architecture that scales without breaking your budget.
Stop playing with AI. Start engineering it for the enterprise.
Contact Shark AI Solutions to discuss your next high-performance engine
Also exploring predictive maintenance? See how we're Using CNC Data Richness to Predict Tomorrow's OEE.