The Fine-Tuning Fallacy: When Enterprises Need (and Don’t Need) LLM Fine-Tuning
A Strategic Guide by SharkAI Solutions
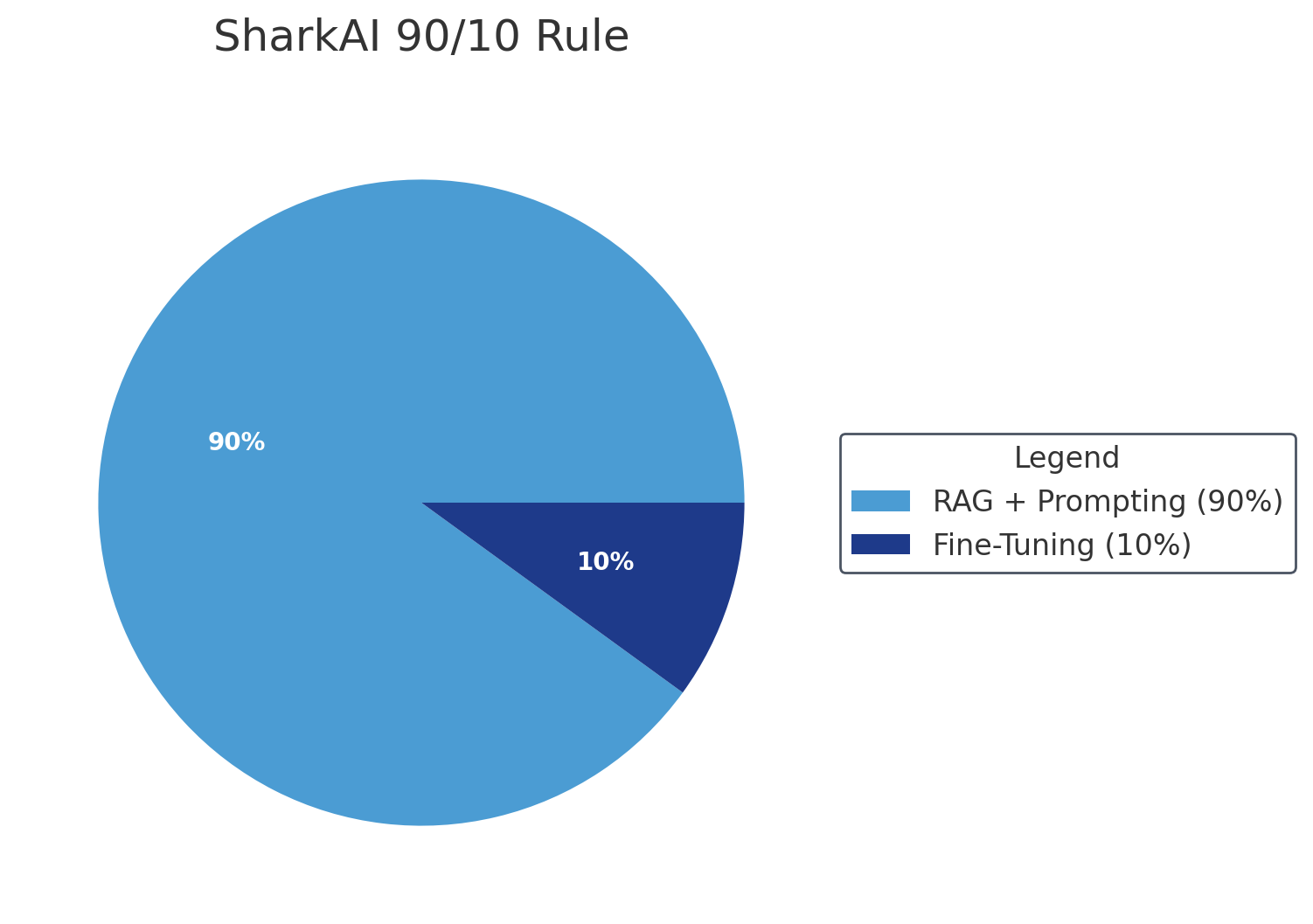
Executive Summary: The SharkAI 90/10 Rule
Enterprises frequently jump into fine-tuning before determining whether it is even necessary. Through large-scale deployments across healthcare, BFSI, manufacturing, logistics, energy, and multi-domain enterprise operations, SharkAI established a simple principle that has saved clients millions:
- 90% of enterprise GenAI use cases should rely on Retrieval-Augmented Generation (RAG) + Prompting
- Only 10% require Fine-Tuning
Fine-tuning is powerful—but only when used in the right context.
The distinction affects cost, compliance, accuracy, scalability, and maintenance.
This guide provides the SharkAI Strategic Decision Framework to choose the right LLMOps architecture from Day 1.
Why This Decision Matters in 2025
The moment a GenAI initiative begins, enterprises feel intense pressure:
- “We should fine-tune our own model so it understands our business.”
- “We need a custom model to reduce dependence on vendors.”
- “Accuracy will improve only if we train on our own data.”
These assumptions appear logical—but are mostly incorrect.
After dozens of enterprise deployments, SharkAI’s conclusion is consistent:
In 9 out of 10 enterprise use cases, fine-tuning increases cost and complexity without improving outcomes.
Most objectives are achieved faster, safer, and more reliably through:
- RAG (Retrieval-Augmented Generation)
- Advanced Prompt Engineering
- Evaluators
- Guardrails & Governance Systems
Fine-tuning is a precision instrument, not a default choice.
When NOT to Fine-Tune (The SharkAI 90% Zone)
Most enterprise GenAI workloads fit into these categories.
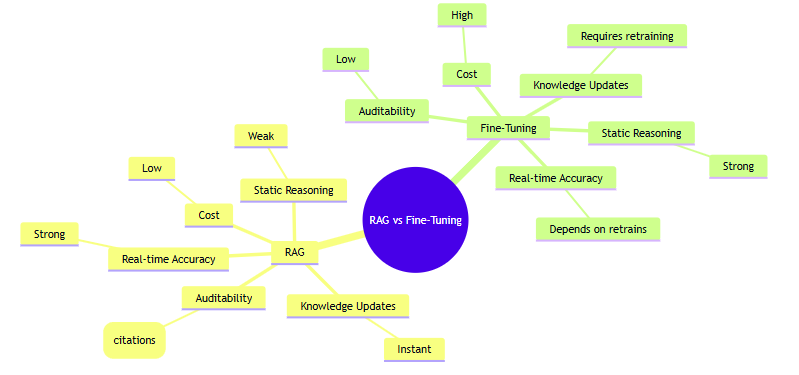
1. When You Need the Model to Use Internal Knowledge (Not “Learn” It)
Fine-tuning does not store enterprise documents as reusable memory.
It only shifts token probabilities—it cannot memorize your organizational knowledge efficiently.
Why RAG Works Better
RAG uses:
- Embedding models (vector representations of text)
- Vector databases (Pinecone, Milvus, Weaviate, Qdrant, LanceDB)
- Retrieval pipelines (BM25 + semantic search)
- Context injection at inference time
RAG grounds the model’s answers in retrieved documents with citation-level traceability.
Case Study: Multi-Domain Enterprise Chatbot Suite
A global operations client needed unified chatbots for:
- HR
- SOP queries
- IT support
- Plant operations
- Policies & compliance
Vendor recommendation: Fine-tune 4–5 domain-specific models.
SharkAI analysis showed this would cost $250k+ annually in retraining alone.
SharkAI Solution:
- Centralized RAG index with 18,000 versioned documents
- Knowledge routing classifier (intent detection)
- Domain-specific prompting
- Context reranking
- Full source citations
Outcome:
- 70% faster time-to-production
- Traceable, audited responses
- Zero retraining cycles regardless of knowledge updates
2. When Knowledge Changes Frequently
Fine-tuned models become stale the moment the source data changes.
Common examples:
- Pricing updates
- Policy changes
- Regulatory requirements
- SOP revisions
- Financial rules
- Compliance updates
Maintenance Cost of Fine-Tuning
Every update requires:
- Re-cleaning training data
- Re-running PEFT/LoRA
- GPU cycles costing $5,000–$50,000 per retrain
- Regression testing & QA
- Redeploying models with version control
- Updating guardrails
This process takes days to weeks.
Maintenance Cost of RAG
- Update document → re-index
- Live in seconds
- No retraining
- Automatic version tracking
If your knowledge changes weekly—or even quarterly—RAG is the only efficient solution.
3. When Auditability and Governance Are Required
Regulators and compliance teams demand:
- Document citations
- Version lineage
- Explanation of reasoning
- Closed-loop audits
- Controlled references
RAG provides:
- Paragraph-level citations
- Explainable retrieval paths
- Timestamped document versions
Fine-tuned models:
- Provide no citations
- Are not explainable
- Cannot prove source origins
For BFSI, healthcare, public sector, aerospace—RAG is mandatory.
4. When the Issue Is Formatting, Style, or Output Structure
If your LLM struggles with:
- JSON schemas
- Structured templates
- Persona consistency
- Writing style
- Length control
- Formatting
These are prompting problems, not training problems.
SharkAI fixes these using:
- Robust system prompts
- Location-aware instructions
- Example-driven prompting (few-shot)
- Output validators
- JSON/YAML schema enforcers
- Rewriting pipelines with evaluators
Fine-tuning for formatting issues is expensive and unnecessary.
When Fine-Tuning IS Required (The Strategic 10% Zone)
Fine-tuning delivers massive value when internal reasoning or behavior patterns must change.
1. Extreme Domain Expertise or Complex Multi-Step Reasoning
General-purpose LLMs lack deep:
- Medical reasoning
- Mechanical troubleshooting
- Aircraft safety logic
- Legal contract reasoning
- Industrial automation workflows
Fine-tuning teaches the model new cognitive patterns.
Case Study: AI Health Expert Clone
A healthcare partner required triage-grade reasoning. SharkAI fine-tuned models on:
- Multi-step diagnostic pathways
- Clinical triage trees
- Medical terminology
- Patient symptom narratives
- Risk stratification patterns
Result:
- Accurate triage-quality explanations
- Context-aware medical reasoning
- High precision in multi-symptom interpretation
- Outperformed GPT-4 and Claude in clinical scenarios
This level of reasoning is impossible with RAG alone.
2. Deep Persona, Empathy, and Psychological Behavioral Modeling
Prompting can create tone, but only fine-tuning creates stable, predictable, repeatable behavior.
Used for:
- Therapy simulations
- Coaching agents
- Sales personas
- HR interviewers
- Behavioral assistants
Case Study: AI Psychotherapist Clone
SharkAI fine-tuned a model on:
- CBT session transcripts
- Reflective listening patterns
- Emotional validation structures
- Safety boundaries
- Non-escalatory response patterns
Outcome:
- Therapist-level persona consistency
- Predictable emotional calibration
- Safe and responsible conversational boundaries
This stability cannot be achieved through prompting alone.
3. Brand-Consistent Image & Creative Style Generation
When visual identity must be consistent across thousands of images, fine-tuning diffusion models is essential.
Full case study:
👉 https://www.sharkaisolutions.com/blog/medium_post4
Case Study: Brand Image Generator
A major enterprise needed 10,000+ marketing visuals with perfect brand consistency.
SharkAI fine-tuned a diffusion model on:
- Logos
- Color palettes
- Typography
- Layout motifs
- Lighting & composition rules
Outcome:
- Image consistency across campaigns
- Instant content generation
- 90% reduction in design cost
- Brand-safe automation
4. High-Precision Classification Tasks
If your classification accuracy target exceeds 95–98%, LLMs are inconsistent.
Fine-tuning small models (BERT, MiniLM, DistilBERT) gives:
- Higher accuracy
- Faster inference
- Lower cost
- Edge deployment capability
Used widely for:
- Phishing detection
- Sentiment analysis
- Toxicity detection
- Contract clause extraction
- Compliance tagging
5. Edge Deployment & Low Latency
Devices requiring <50ms latency or offline inference cannot use large LLMs.
Fine-tuning enables:
- Distillation
- Quantization
- LoRA adapters
- Size reduction
- Domain optimization
This allows compact models to perform like large ones.
Used in:
- IoT gateways
- Mobile apps
- Industrial systems
- On-prem appliances
- Offline environments
The SharkAI LLMOps Decision Framework
| Requirement | Prompting | RAG | Fine-Tuning |
|---|---|---|---|
| Add internal knowledge | ❌ | ✅ | ❌ |
| Improve formatting | ✅ | ❌ | ❌ |
| Deep domain reasoning | ⚠️ | ⚠️ | ✅ |
| Brand voice/persona | ⚠️ | ❌ | ✅ |
| Reduce hallucinations | ❌ | ✅ | ❌ |
| High-accuracy classification | ❌ | ❌ | ✅ |
| Edge/latency optimization | ❌ | ❌ | ✅ |
SharkAI’s Default Architecture Pipeline
RAG → Prompting → Evaluators → Fine-Tuning (only when justified)
This ensures:
- Faster development
- Lower maintenance
- Governance & auditability
- Version safety
- Multi-domain scalability
Partner With SharkAI to Build the Right LLM Solution
Most enterprises overspend on fine-tuning and underutilize RAG and prompting.
SharkAI helps you reverse this.
We specialize in:
- RAG-first architectures
- LLMOps excellence
- Governance and compliance
- Enterprise safety layers
- Cost-optimized model pipelines
- Selective fine-tuning for high-ROI use cases
Your Next Step
Schedule a 15-minute consultation with a SharkAI Principal Architect:
https://www.sharkaisolutions.com/contactus
You will receive:
- A RAG-first, cost-optimized architecture
- An audit-ready, compliant design
- A roadmap that uses fine-tuning only where it delivers ROI
- Guidance on scale, performance, and governance
SharkAI builds GenAI systems that are smarter, faster, safer, and built for enterprise scale.